Stop Re-Explaining Your Codebase to Your AI Agent
AI coding agents can write code, but each session starts without knowledge of your repo structure, conventions, or prior work. Scaffold is an open-source tool that gives agents persistent, machine-readable project context through structured briefing files, with explicit controls to detect and limit drift.
If you use AI coding agents regularly, a pattern emerges.
You start a session. You re-explain the repo. The agent makes a change. Then asks you to run tests and paste the output. Repeat.
At that point, the agent isn’t autonomous. You’re acting as a transport layer between the model and your own codebase.
This isn’t a model-quality problem. Modern coding agents can write code.
It’s a continuity problem.
Each session starts without knowledge of your repo structure, conventions, test commands, or prior work. That context bootstrap is pure overhead.
Scaffold exists to remove it.
Scaffold is an open-source tool for giving AI coding agents persistent, machine-readable project context, with explicit controls to detect and limit drift.
Get started
Scaffold is distributed as a Claude Code skill. Install it from the marketplace:
/plugin marketplace add autoencoders/skills
/plugin install scaffold@autoencodersThen, in any repo:
scaffold initThis generates the briefing file at the root of your repository. It scans your codebase — build files, packages, scripts, services, env files — and produces a structured context file that agents can consume at session start.
From there, two commands:
scaffold sync # regenerate derived context, preserve human sections
scaffold check # validate freshness and completenessThat’s the entire surface area. The rest of this post explains why it’s built this way.
Persistent context, not better prompts
We didn’t attempt to solve “agent memory.”
We asked a narrower question:
What context can an agent reliably consume at the start of a session?
The answer is: files.
Not environment variables. Not a database. Not injected system prompts. Files work because every agent environment can read them, they’re version-controlled by default, they’re inspectable by humans, and they don’t depend on any platform-specific memory API. The abstraction is the file system you already have.
Scaffold maintains a single, structured briefing file at the root of the repository. It is not prose documentation. It is an operational artifact.
It contains:
- project structure and package boundaries
- commands for tests, linting, and services
- core conventions (logging, error handling, tooling)
- human-owned sections for:
- current work
- known issues
- architectural decisions (with rationale)
Agents read this file at session start. No prompt scaffolding. No manual recap.
Keeping context accurate
The briefing file is regenerated by scanning the codebase:
- build and dependency metadata
- packages and entry points
- Makefiles and scripts
- container and service definitions
- env files, specs, migrations
Derived sections are refreshed automatically. Human-written sections are preserved verbatim.
scaffold syncThe operation is idempotent.
Effect on workflow
Before Each session begins with explanation.
After The agent reads the briefing file. Work resumes.
This does not increase agent intelligence. It makes sessions resumable.
Failure modes and controls
Documentation drift
Without enforcement, context decays.
Scaffold includes a validation pass:
scaffold checkIt verifies:
- freshness of the briefing file
- presence of required artifacts
- unfilled templates
- tooling expectations
Results are explicit:
scaffold check
✓ Briefing file .............. up to date
✓ Architecture decisions ..... present
⚠ Changelog .................. last updated 6 days ago
✗ Bug log .................... missing
1 failed, 1 warning, 2 passed
Fix with: scaffold sync --fixContext drift is treated as a detectable failure state, not something you notice three sessions later when the agent hallucinates a test command that was renamed last week.
Agent fallibility
Agents will sometimes fail to update context.
Scaffold assumes this:
- ownership boundaries are explicit (derived sections belong to the tool, human sections belong to you)
- checks surface stale or missing updates
- failures are visible and actionable
The system is designed around imperfect agents.
Scope and constraints
Scaffold is opinionated. It enforces:
- structured logging
- architectural decision records
- changelog and bug log
- consistent project layout
The opinions exist to make the automation possible.
Scaffold does not make agents autonomous or remove the need for review. It addresses one problem: continuity across sessions.
What remains unsolved
Scaffold stabilizes the start and end of agent sessions. It does not address what happens in the middle.
An agent can still make poor architectural choices, ignore conventions that are clearly documented in the briefing file, or produce code that passes checks but misses intent. Scaffold gives agents the context to do better work. It doesn’t guarantee they will.
The open questions are around feedback loops: how to make agents internalize corrections across sessions, and how to detect semantic drift (not just structural drift) in the artifacts they produce. These are harder problems. Scaffold doesn’t pretend to solve them.
Implementation notes
Scaffold is available as open source at github.com/autoencoders/skills.
No additional abstractions are required beyond file access and a command runner. The current distribution is a Claude Code skill, which integrates directly with agent sessions and tooling. The underlying approach — structured briefing files, idempotent regeneration, and explicit health checks — is model-agnostic and applicable to other agent environments (including Codex-style workflows).
Appendix A: Claude Code vs Codex integration constraints
Both Claude Code and Codex-style environments provide the three primitives Scaffold requires: a readable file system, a way to run commands, and a point at which context is loaded. The difference is where integration happens.
Claude Code
Claude Code provides these natively. The briefing file is automatically read at session start. Sync and check commands run as part of the agent workflow. Documentation updates are encouraged through convention and checks. No wrapper code required.
Codex-style environments
Codex-style systems provide the same primitives externally. The briefing file must be explicitly referenced or injected into the prompt. There is no implicit session-start read step — behavior depends on the surrounding orchestration layer. Integration occurs in the runner or wrapper, not the agent itself. Health checks and regeneration remain identical.
The delta
Scaffold assumes only that these three primitives exist. Claude Code happens to provide them with zero configuration. Codex-style systems require you to wire them up. The tool itself doesn’t change.
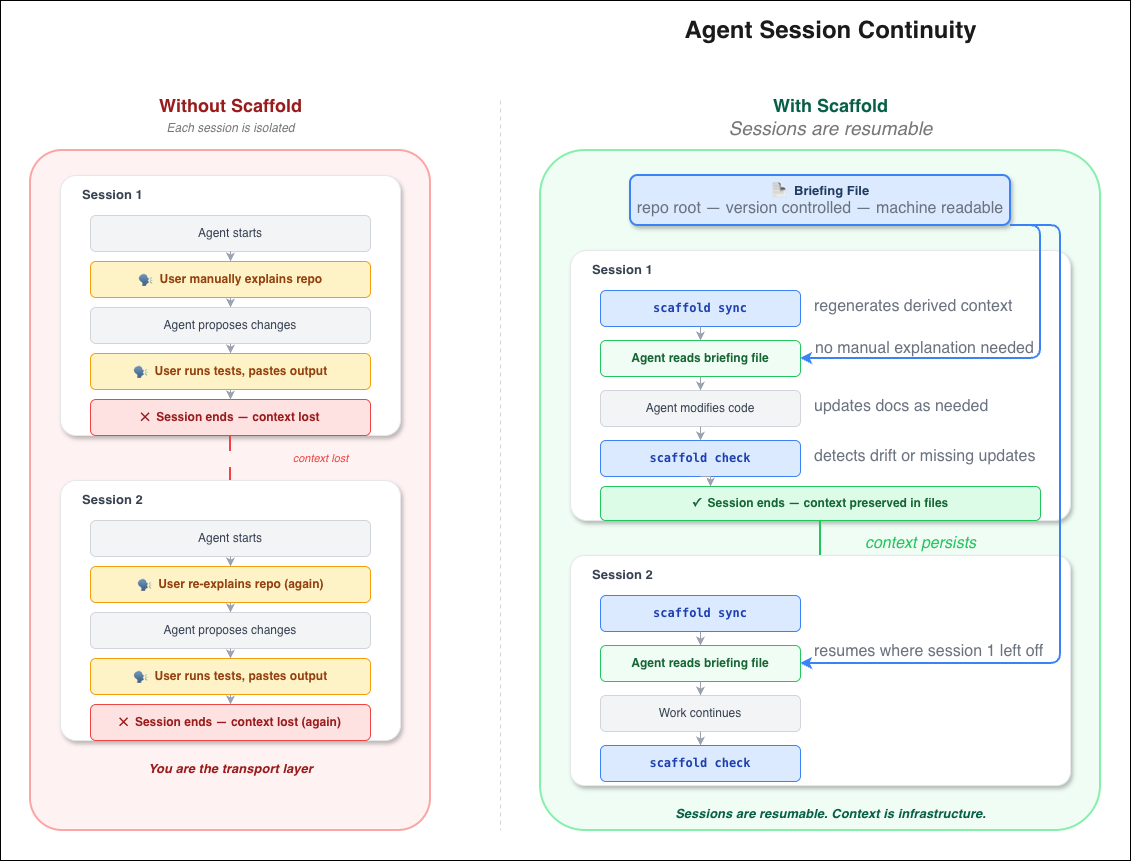
Appendix B: Scaffold in the agent execution loop
Scaffold inserts a context stabilization step before and after agent work.
Without scaffold
- Agent session starts
- User manually explains context
- Agent proposes changes
- User runs tests and pastes output
- Session ends
- Context is lost
Each session is isolated.
With scaffold
- Context sync —
scaffold syncregenerates derived context; human-written sections remain unchanged - Session start — Agent reads the briefing file
- Work phase — Agent modifies code; documentation artifacts may be updated
- Validation —
scaffold checkdetects drift or missing updates - Session end — Context is preserved in files
Properties
Context is externalized from the model. State survives across sessions. Drift is detectable.
Scaffold does not alter agent reasoning. It constrains the environment in which reasoning occurs.