Serverless Warm Memory: A Distinct Service Category
Serverless platforms optimized for stateless, elastic compute. But memory-bound workloads need the opposite: warm RAM, fast local disk, and sticky routing. This isn't better serverless. It's a different abstraction entirely, one that treats memory as the product rather than an implementation detail.
The real value is warm state, locality, and cache, not generic compute.
The limits of today’s serverless
Platforms like AWS Lambda, Google Cloud Run, and Fly.io Machines share a common abstraction: stateless requests handled by ephemeral containers that scale up and down on demand. This model works well when requests are independent, data fits in memory or comes from fast remote stores, cold starts are acceptable, and compute is the bottleneck.
But it breaks down when each request reads gigabytes of data, when the same user sends consecutive requests over similar data, when memory bandwidth dominates CPU, or when the working set is much larger than RAM but benefits from caching. In these cases, statelessness is not a feature. It’s a tax.
The class of problems we keep fighting
Consider workloads like interactive analytics over large datasets, matrix and tensor queries, document or embedding search over large corpora, time-series slicing, and scientific or financial analysis pipelines.
These workloads share common characteristics. They typically read one to three gigabytes per request. They run for ten to fifteen seconds. They are memory-bound, not CPU-bound. They exhibit strong temporal locality, where follow-up queries overlap heavily with previous ones. And throughput matters more than raw parallelism.
Running these on pure serverless results in constant cache misses, repeated object storage reads, massive egress costs, and poor tail latency. What these workloads want is warm state, not infinite scale.
Warm memory is the product
Most platforms treat memory as something you allocate per request, or something you get for free if the container happens to be reused. That’s backwards for memory-bound systems.
For these workloads, warm RAM is the expensive, valuable resource. Fast local disk is the second tier. Remote object storage is the cold backup. The performance differences are stark:
RAM → microseconds
NVMe / SSD → milliseconds
Object storage → tens to hundreds of millisecondsA platform that ignores this hierarchy leaves performance on the table. A platform that embraces it treats memory as the product, with compute attached.
Locality beats elasticity
Here is a key observation: serving the same user twice on the same machine is often worth more than adding ten more machines.
Locality enables reused decoded data structures, OS page cache hits, hot disk blocks, and precomputed indices. Elasticity, by contrast, spreads related work across machines, destroys cache warmth, and increases total I/O.
This doesn’t mean never scale. It means scale deliberately and keep state warm as long as possible. The goal is not maximum utilization. The goal is minimum data movement.

A missing service category
What’s missing is a platform that offers long-lived workers, large memory footprints, fast local disks, sticky routing, bounded concurrency, and explicit backpressure. Not functions as a service, but memory as a service with compute attached.
This is a fundamentally different abstraction from traditional serverless.
What serverless warm memory actually means
A serverless warm memory platform differs from traditional serverless in several concrete ways.
Workers stay alive for minutes or hours, not seconds. Memory is reused intentionally, not accidentally. Cold starts are rare, not normal. This is the foundation: warmth by design.
Stickiness becomes a first-class primitive. Requests include a routing key:
user_id
user_id:dataset_id
conversation_idThe platform ensures that the same key routes to the same worker while it lives, preserving locality automatically. Developers declare affinity; the platform enforces it.
Each worker has hundreds of gigabytes of local NVMe with managed eviction and a stable mount point. Developers don’t build caching systems. They consume one. The platform handles what to keep and what to evict.
Concurrency is explicit and bounded:
this worker runs at most 16 jobs concurrentlyThis prevents I/O collapse and keeps latency predictable. Work is queued, backpressure is real, and overload is visible and controlled.
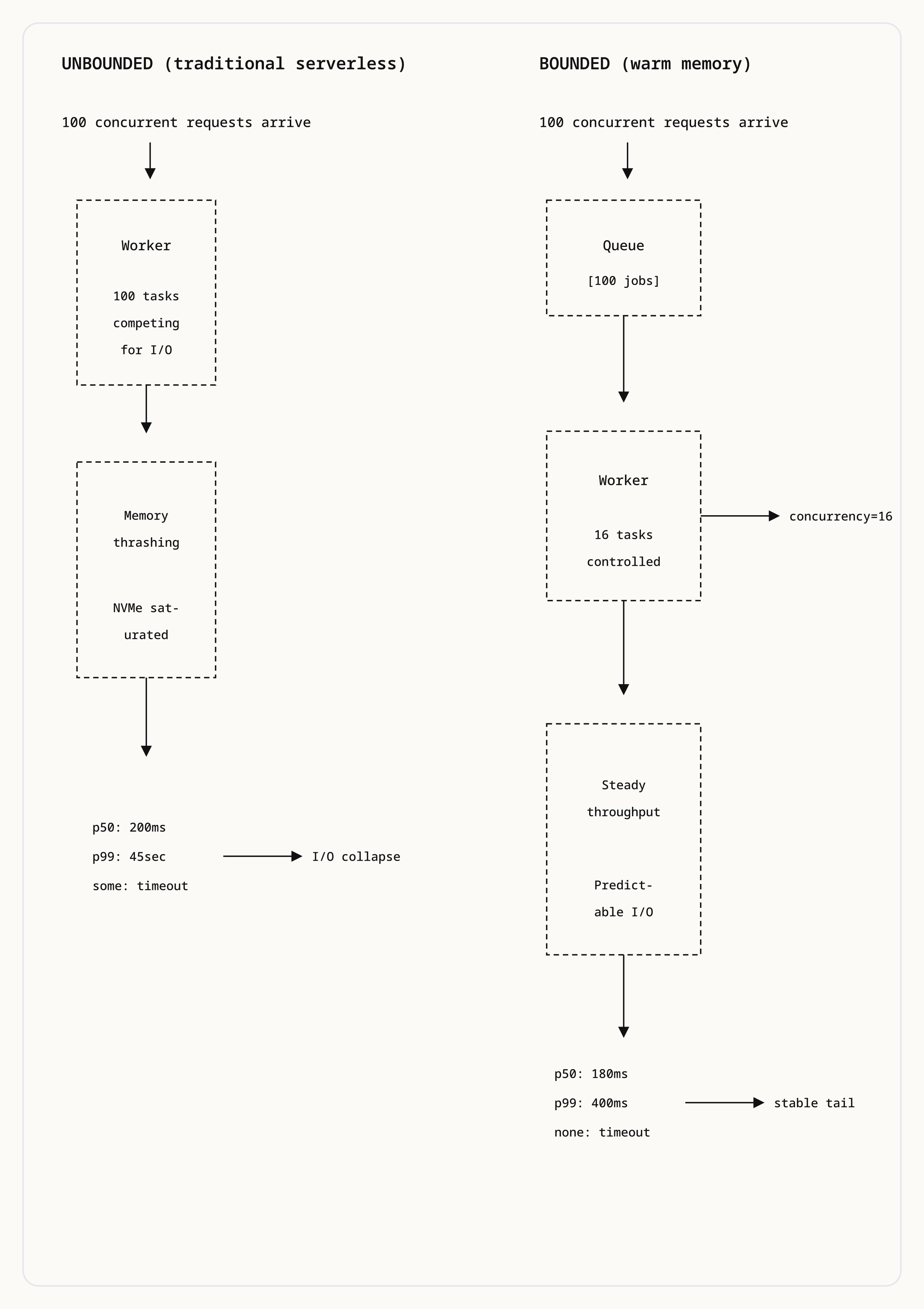
This can still feel serverless
Despite using long-lived workers, the developer experience can remain serverless:
memrun deploy \
--image my-worker:latest \
--memory 32Gi \
--disk 600Gi \
--concurrency 16 \
--sticky-key user_id:dataset_idOr even:
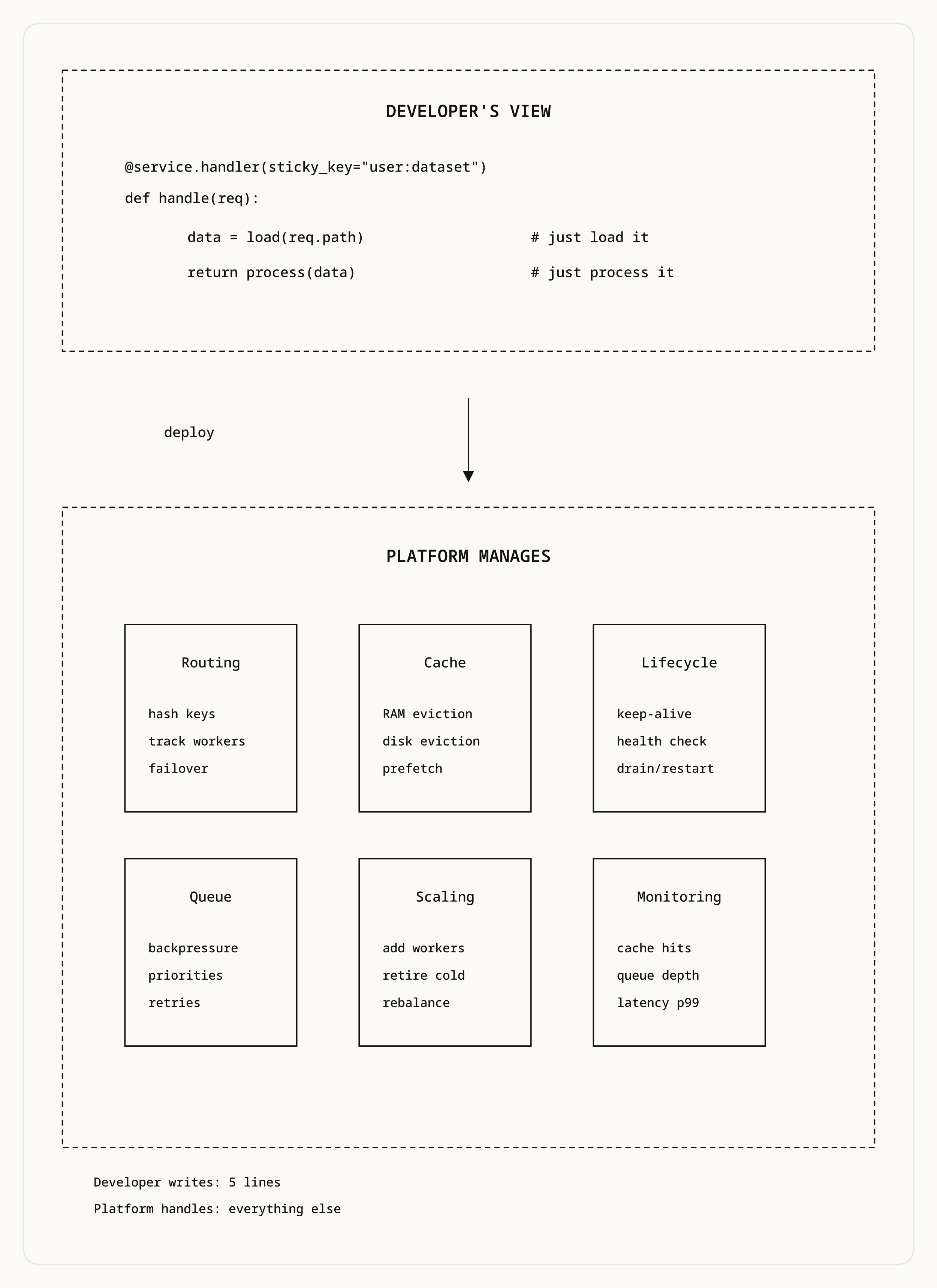
@service.handler(sticky_key="user_id:dataset_id")
def handle(req):
return run_query(req)The developer never provisions machines manually, thinks about cache eviction policies, manages routing tables, or handles retries. They deploy logic. The platform owns the memory.
The abstraction boundary shifts. Traditional serverless abstracts away machines. Serverless warm memory abstracts away machines and cache management and locality routing. The developer’s mental model is simpler, not more complex.
Why hyperscalers don’t offer this yet
This model conflicts with hyperscaler economics. They optimize for multi-tenant elasticity. Statelessness maximizes utilization. Warm state reduces fleet fungibility. From the platform provider’s perspective, dedicated warm memory for one customer is capacity unavailable for another.
But for users, memory-bound workloads want lower utilization, because locality is worth more than elasticity. This is why people keep rebuilding similar systems: Redis-backed workers, stateful microservices, bespoke analytics backends. They’re all reinventing the same missing abstraction because the platforms don’t provide it.
Cost efficiency through constraint
A counterintuitive insight: memory-bound workloads get cheaper when you stop scaling.
With fixed worker pools, predictable memory usage, cheap local disks, and minimal data movement, cost becomes linear, stable, and easy to reason about. You trade peak elasticity for sustained efficiency. For workloads with predictable load and strong locality, this is the right tradeoff.
The economics flip. Traditional serverless charges for compute time and rewards minimizing it. Serverless warm memory charges for reserved capacity and rewards maximizing cache hit rates. Different cost models for different workload shapes.
This is not better serverless
This category does not replace AWS Lambda, Cloud Run, or App Runner. It complements them.
Use classic serverless when requests are independent, compute dominates, and latency tolerance is high. Use serverless warm memory when data reuse matters, memory bandwidth is the bottleneck, locality is everything, and predictability beats elasticity.
The distinction is not quality. It’s fit. A hammer is not better than a screwdriver. They solve different problems.
The mental model shift
The shift is from asking “how do I scale this to zero?” to asking “how do I keep the right memory hot?”
Traditional serverless optimizes for the cold path: fast startup, stateless execution, quick teardown. Serverless warm memory optimizes for the warm path: preserve state, reuse computation, minimize data movement.
Both are valid. The question is which matches your workload.
The future of data-intensive systems isn’t just faster CPUs or bigger clusters. It’s treating warm memory and locality as first-class resources.
If traditional serverless made compute disposable, serverless warm memory makes state valuable again.