Stateful by Design: The Missing Serverless Abstraction
Serverless removed servers from the developer's mental model, but it also removed state from first-class support. For data-intensive workloads, that tradeoff is increasingly costly. We built memrun to prove that warm, locality-aware workers can remain serverless in feel while eliminating the state tax that stateless platforms impose.
Why warm, owned state deserves to be a first-class primitive
Serverless platforms won by making compute stateless, disposable, and elastic. That abstraction removed enormous operational burden. It also quietly dropped an entire class of workloads from first-class support.
For memory-bound, data-intensive, locality-sensitive systems, state is not incidental. It is the workload. Every time a Lambda or Cloud Run container starts cold, reads 2GB from S3, decodes it into working memory, serves one request, and then gets killed — that’s the state tax. Not a minor overhead. The dominant cost.
This paper argues that stateful-by-design execution is the missing serverless abstraction. We built a platform called memrun that treats warm memory and locality as first-class primitives, and the results confirm what anyone running data workloads already suspects: the stateless model is wrong for this class of problems.
How statelessness became dogma
Serverless didn’t win because it was fast. It won because it was simple.
Stateless execution eliminated machine management, capacity planning, long-lived processes, and much of the complexity around failure recovery. Developers could deploy code without thinking about where it ran or how many instances existed. The platform handled all of that.
But somewhere along the way, statelessness stopped being a tool and became a rule. Today’s platforms implicitly assume that if something is stateful, it isn’t serverless. That assumption is wrong more often than people realize.
The state tax
Stateless compute works well when requests are independent, data is small or remote, cold starts are acceptable, and CPU dominates cost. Many web applications fit this profile.
But there’s a growing class of workloads where these assumptions collapse. Systems where data volumes reach hundreds of gigabytes. Where memory bandwidth dominates runtime. Where requests are correlated over time. Where data movement costs more than computation.
Interactive analytics over large datasets. Matrix and tensor computations. Vector search over large corpora. Document processing pipelines. These workloads share common traits: they read one to three gigabytes per request, run for ten to fifteen seconds, exhibit strong temporal locality, and repeatedly access overlapping data.
The state tax in numbers: each cold request pays the full cost of fetching from object storage (tens to hundreds of milliseconds per object), deserializing into working structures, and building in-memory indices. A warm request skips all of that. For a 2GB working set, that’s the difference between 15 seconds and under 1 second.
Recomputing is cheap. Reloading state is not.

The illusion of “stateless, but cached”
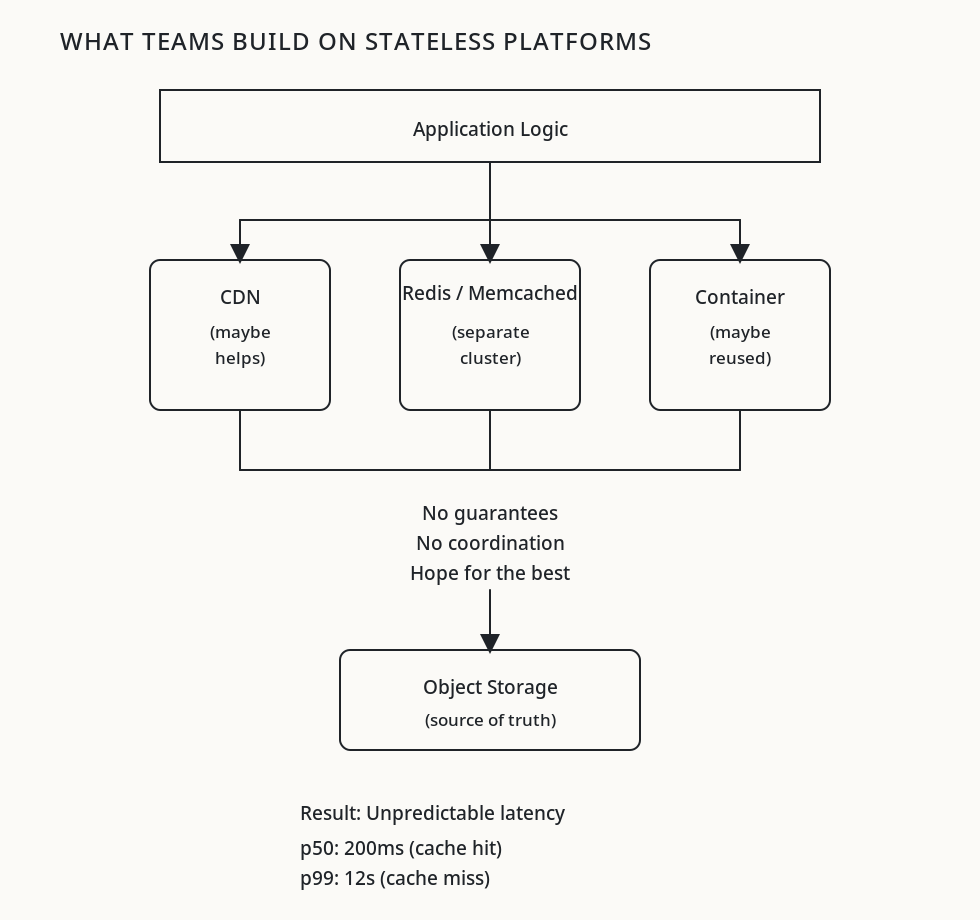
Teams respond to these problems with a familiar refrain: “We’ll keep it stateless and add caching.”
In practice, this means Redis sidecars, hoping containers get reused, and best-effort CDN layers. This is accidental state. The platform has no model of what state exists, where it lives, or how to schedule around it.
The problems with accidental caching:
- No guarantee your container gets reused. Cold starts wipe everything.
- Redis/Memcached adds network hops. For 2GB working sets, that’s still slow.
- No locality awareness. Related requests scatter across workers.
- No eviction policy tuned to your access pattern.
- Cache warmup is your problem, not the platform’s.
State becomes something teams fight to preserve rather than something the platform helps manage.
Making state intentional
A stateful-by-design platform doesn’t pretend state doesn’t exist. It makes state explicit, bounded, owned, and reconstructible.
In memrun, this takes a concrete form. Each worker gets a SharedWorkerContext that persists across requests. This context owns an LRUCache backed by NVMe storage (up to 600GB per worker) and an in-memory object store for decoded structures. The platform — not the developer — manages what stays warm and what gets evicted.
The cache is configured at the platform level:
CacheConfig(
cache_dir="/var/lib/memrun/cache/{service_name}/",
max_size_bytes=600 * 1024**3, # 600 GB
max_items=100_000,
ttl_seconds=None, # No expiry, pure LRU
cleanup_interval_seconds=300,
)Workers are long-lived by design, not by accident. State exists because the platform allows it to exist and schedules work around it. This is fundamentally different from hoping containers stay warm.
Locality as a scheduling primitive
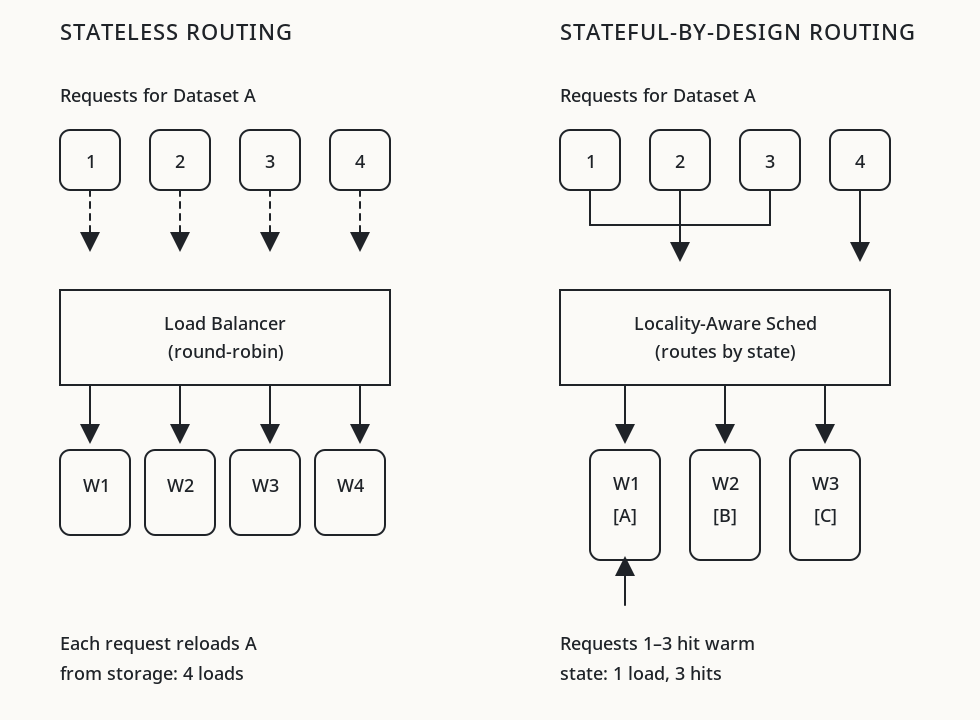
In stateless systems, every request is equal, history is ignored, and locality is accidental. The scheduler optimizes for utilization, treating all workers as interchangeable.
In memrun, scheduling is biased by state. The mechanism is Kafka partition keys. When a service declares a sticky_key (e.g., "user_id:dataset_id"), the platform hashes that key to a partition, and each partition is consumed by exactly one worker in the consumer group. Same key, same worker, same warm cache.
@svc.handler(sticky_key="user_id:dataset_id")
async def handle(ctx, req):
data = await ctx.get_or_fetch(req["dataset_path"])
# Second request with same user_id:dataset_id hits warm cache
return process(data, req["params"])The get_or_fetch method on WorkerRequestContext checks the local NVMe-backed LRUCache first. Only on cache miss does it fetch from S3. Subsequent requests with the same sticky key route to the same worker, hitting warm disk or even OS page cache.
This isn’t complex routing logic. It’s Kafka’s consumer group protocol doing what it was designed to do — but applied as a locality primitive rather than just a load distribution mechanism.
Rethinking failure
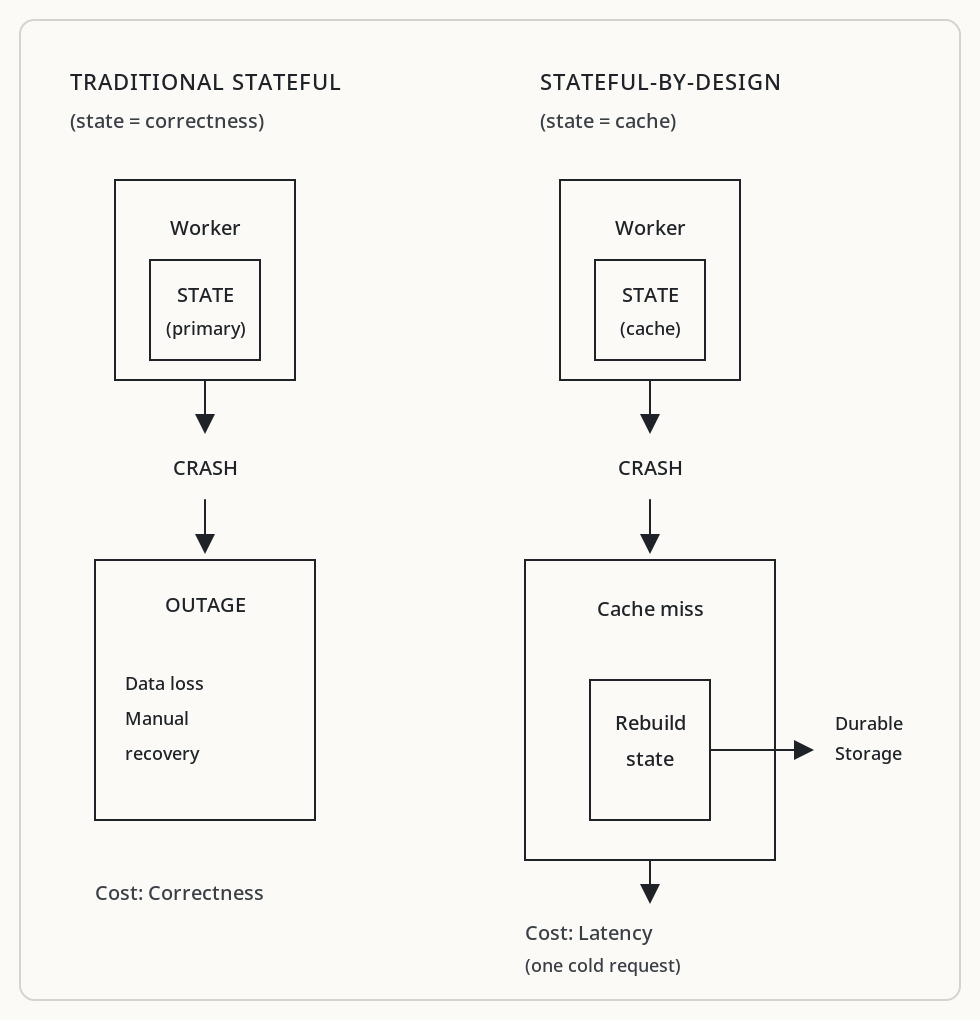
Stateful systems are often criticized as fragile. This is true when state is implicit, when state loss breaks correctness, and when recovery is manual.
In memrun, state is cache-like. A worker crash causes cache misses, not outages. The LRUCache persists its index to index.json, so a worker restart can recover what’s on disk. But even if that’s lost, the worker reconstructs state from S3 on the next cache miss. Warm state is an optimization, never a correctness requirement.
The _load_index() method attempts to restore the cache map from disk on startup. If it fails, the cache starts empty and refills organically as requests arrive. The system never returns errors because state was lost — it returns correct results, just slower until the cache is warm again.
This matters operationally. When memrun’s Scheduler does a rolling deployment, it provisions new workers, waits for them to become ready (confirmed via heartbeat), then deprovisions old ones. Cache warmth transfers implicitly: the new worker starts cold, but Kafka’s sticky routing ensures it begins accumulating the same data its predecessor held.
This is still serverless
Stateful-by-design does not mean hand-managed servers, manual scaling, or bespoke recovery logic. The developer experience in memrun is:
from memrun import MemoryService
svc = MemoryService(
name="analytics-engine",
memory="32Gi",
disk="600Gi",
max_workers=10,
concurrency=16,
)
@svc.handler(sticky_key="user_id:dataset_id")
async def handle(ctx, req):
data = await ctx.get_or_fetch(req["s3_path"])
return analyze(data, req["query"])
svc.deploy()No machine provisioning. No cache configuration. No routing tables. The developer declares what matters (sticky_key, memory, disk, concurrency) and the platform handles the rest: Hetzner VMs provisioned via cloud-init, Kafka topics created per service, NVMe cache managed with LRU eviction, heartbeats every 10 seconds, graceful shutdown on SIGTERM.
The abstraction boundary shifts. Traditional serverless abstracts away machines. Stateful-by-design abstracts away machines and cache management and locality routing.
Why this abstraction didn’t exist sooner
This model is uncomfortable for hyperscaler economics. It reduces worker fungibility, which lowers fleet utilization. Dedicated warm memory for one customer is capacity unavailable for another.
But for users, the tradeoffs favor stateful-by-design: reduced data movement, predictable latency, and lower total cost for state-heavy workloads. A single warm worker serving 16 concurrent requests from cache beats 16 cold Lambda invocations each fetching from S3.
The abstraction was missing not because it was impossible, but because it optimized for the wrong incentives. Platform providers naturally optimize for their own efficiency. Users need platforms that optimize for workload efficiency.
The state tax is real, and it compounds
As datasets grow faster than network bandwidth, and as interactive data workloads become normal, stateless compute stops being the default solution.
The next evolution of serverless is not faster cold starts or more aggressive autoscaling. It is treating state as a first-class resource. Not abandoning stateless compute — that model remains ideal for many workloads. But recognizing that some workloads are fundamentally state-bound, and that pretending otherwise forces teams to build fragile workarounds for problems the platform should solve directly.
We built memrun because we kept paying the state tax on every project. It got old.